メモ
レビューアの立場で問題のスコープを広げすぎないように注意する
ファイルの先頭と末尾の空行を削除するだけのCLIを作った
もうsedのコマンドの検索はしないぞ github.com
プルリクエストが承認+テストをパスしたら通知するmacOSアプリを作った
プルリクエストがマージ可能になったらいち早く知りたいので、承認+テストをパスしたら通知を送るmacOSのアプリを作った。
approve不要なPRについてはテストが完了した時点で通知がくる(はず)。 テストがこけても通知が来る。rejectされても通知が来る。要はステータスが確定したら通知が来る。
Notificationsをみてもいいんだけど、approveやテスト以外の通知もくるので専用に作ってみた。 Notifications全般の通知を受け取りたいならGitifyを使った方がいいと思う。
通知はこんな感じ。
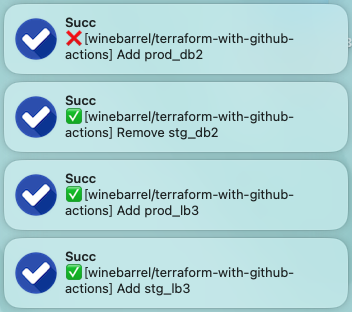
メニューバーのアイコンをクリックするとステータスが確定したPRの一覧が出る。
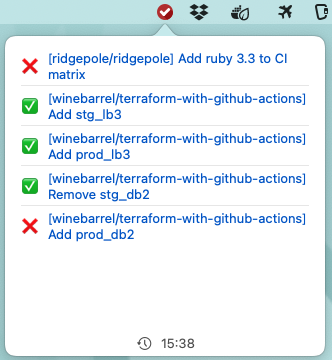
あとステータスが確定したPRがないときは、メニューバーのアイコンが黒に変わる。
![]()
設定画面で検索条件を変えられるので、特定のorgだけにするとか、一部orgを除外するとかできる。
実装
以下のようなGraphQLを実行して、PR一覧とテストのステータスをまとめて取得している。
https://github.com/winebarrel/Succ/blob/main/Succ/Github/SearchPullRequests.graphql
query SearchPullRequests($query: String!) { search(type: ISSUE, last: 100, query: $query) { nodes { ... on PullRequest { repository { name owner { login } } title url reviewDecision commits(last: 1) { nodes { commit { url statusCheckRollup { state } } } } } } } }
取得したPRのステータスを見て通知するかどうかを判断。
https://github.com/winebarrel/Succ/blob/main/Succ/PullRequest.swift
private func updateNodes(_ value: GraphQLResult<Github.SearchPullRequestsQuery.Data>) { var fetchedNodes: Nodes = [] value.data?.search.nodes?.forEach { body in if let pull = body?.asPullRequest { let reviewDecision = pull.reviewDecision if reviewDecision != nil && reviewDecision != .approved && reviewDecision != .changesRequested { return } guard let commit = pull.commits.nodes?.first??.commit else { return } guard let state = commit.statusCheckRollup?.state else { return } if state != .success && state != .failure && state != .error { return } let node = Node( owner: pull.repository.owner.login, repo: pull.repository.name, title: pull.title, url: pull.url, reviewDecision: reviewDecision?.rawValue ?? "", state: state.rawValue, commitUrl: commit.url, success: (reviewDecision == nil || reviewDecision == .approved) && state == .success ) fetchedNodes.append(node) } }
Golangの構造体の情報をダンプするライブラリを作った
Golangの構造体の情報をダンプするライブラリを作った。
使い方
こういう感じの設定用structがあったとして
type config struct { Home string `env:"HOME,required"` Port int `env:"PORT" envDefault:"3000"` Bar *subconfig `envPrefix:"SUB_"` } type subconfig struct { Password string `env:"PASSWORD,unset,required"` IsProduction bool `env:"PRODUCTION"` }
ダンプしてJSONで出力できる。
func main() { var c config ss := tipper.Dump(c) //ss := tipper.DumpT[config]() fmt.Println(ss[0].Fields[0]) //=> "{Password string [{env PASSWORD [unset required]}]}" fmt.Println(ss) }
[ { "name": "main.subconfig", "fields": [ { "name": "Password", "type": "string", "tags": [ { "key": "env", "name": "PASSWORD", "options": [ "unset", "required" ] } ] }, // ...
ユースケース
「Golangのプログラムでconfig構造体にフィールドを追加したが、ECSタスク定義に環境変数を追加していなかったためデプロイしたらCIがこけた」ということがたまにあるので、プログラム自身に必要な環境変数を出力させて、テストでECSタスク定義の環境変数と比較する…というようなユースケースを考えている。
上記の例だと、必須な環境変数の一覧をjqでとれる。
$ go run main.go | jq -r '.[].fields[] | select(.tags).tags[] | select(.key == "env" and (.options // [] | contains(["required"]))).name' PASSWORD HOME
おまけ: Struct Tagのパース
このライブラリではStruct Tagのパースに https://github.com/fatih/structtag を使っている。 キーから値を取得するだけなら、refrect.StructTag.Get()でできるが、すべてのキーを取得するようなことはできないので。
同様のライブラリはいくつかあるが、アクティブに更新されているものは見つけられなかった。
- https://github.com/moznion/go-struct-custom-tag-parser
- https://github.com/execjosh/structtag
- https://github.com/go-mods/tags
実装自体がシンプルなためあまり問題になることはないと思うが、できれば標準ライブラリでサポートしてほしい…
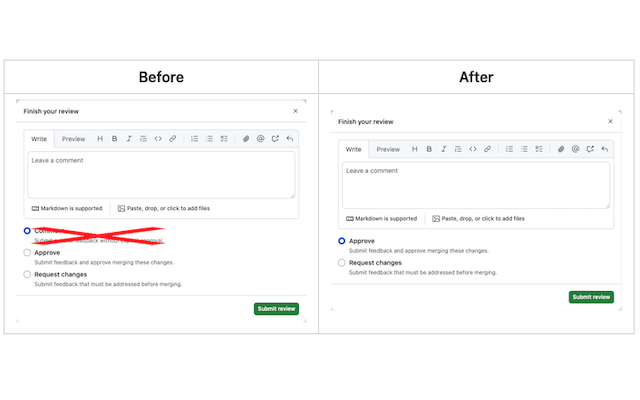
GitHubの「Finish your review」から「Comment」を消すChrome拡張を作った
https://chromewebstore.google.com/detail/github-hide-finish-commen/ejflccgjhcloeienodjdmngdhockjbdf
10回に1回ぐらい「Approveしたと思ったらCommentだった」ということがあるので、Finish your reviewからCommentを消す拡張を作ってみた。
シングルバイナリで動くERBのテンプレートプロセッサーを作った
本体は ERB.new().result を呼ぶだけで、それをmrubyでdarwin/linuxのx86_64/aarch64向けにビルドした。
以下のようにシングルバイナリプログラムを通してテンプレートファイルを処理できる。
<%-
to = ENV["MAIL_TO"]
priorities = ENV["PRIORITIES"].split(",").map(&:strip)
-%>
From: James <james@example.com>
To: <%= to %>
Subject: Addressing Needs
<%= to[/\w+/] %>:
Just wanted to send a quick note assuring that your needs are being
addressed.
I want you to know that my team will keep working on the issues,
especially:
<%# ignore numerous minor requests -- focus on priorities %>
<%- priorities.each do |priority| -%>
* <%= priority %>
<%- end -%>
Thanks for your patience.
James
$ export MAIL_TO="Community Spokesman <spokesman@example.com>" $ export PRIORITIES="Run Ruby Quiz,Document Modules,Answer Questions on Ruby Talk" $ minierb mail.erb From: James <james@example.com> To: Community Spokesman <spokesman@example.com> Subject: Addressing Needs Community: Just wanted to send a quick note assuring that your needs are being addressed. I want you to know that my team will keep working on the issues, especially: * Run Ruby Quiz * Document Modules * Answer Questions on Ruby Talk Thanks for your patience. James
Dockerコンテナを動かすときに設定値の注入のため環境変数経由で設定ファイルを書き換えることがよくある。 sedで頑張っているDockerイメージもあるし、Docker社の提供するnginxイメージだと組み込みでenvsubstがついてくる。
しかし、単純にプレースホルダを環境変数で置換するだけだと、全然機能が足りないと思っていて、条件分岐や繰り返し、デフォルト値の設定が欲しくなる。 Rubyには組み込みでERBが含まれているが、nginxなどのコンテナにRubyランタイム一式をインストールはしたくない。 そうすると選択肢が限られてきて、自分はGoのテンプレートが使えるsigilを使うことが多かった。
Goのテンプレートは個人的には結構好きだが、パイプラインのような書き方を好まない人もいそうだなとか、もう少しだけテキスト処理を便利にしてほしいなどのニーズがありそうだな…ということで、minierbを作ってみた。
他のエンジニアがDocker向けにどのようなテンプレートプロセッサーを利用しているのか、とても気になる。
